The Model Is Not the Problem
Most agent failures are not model failures. They are configuration, context, and environment failures. The case for harness engineering and why we built Spore.
The Model Is Not the Problem
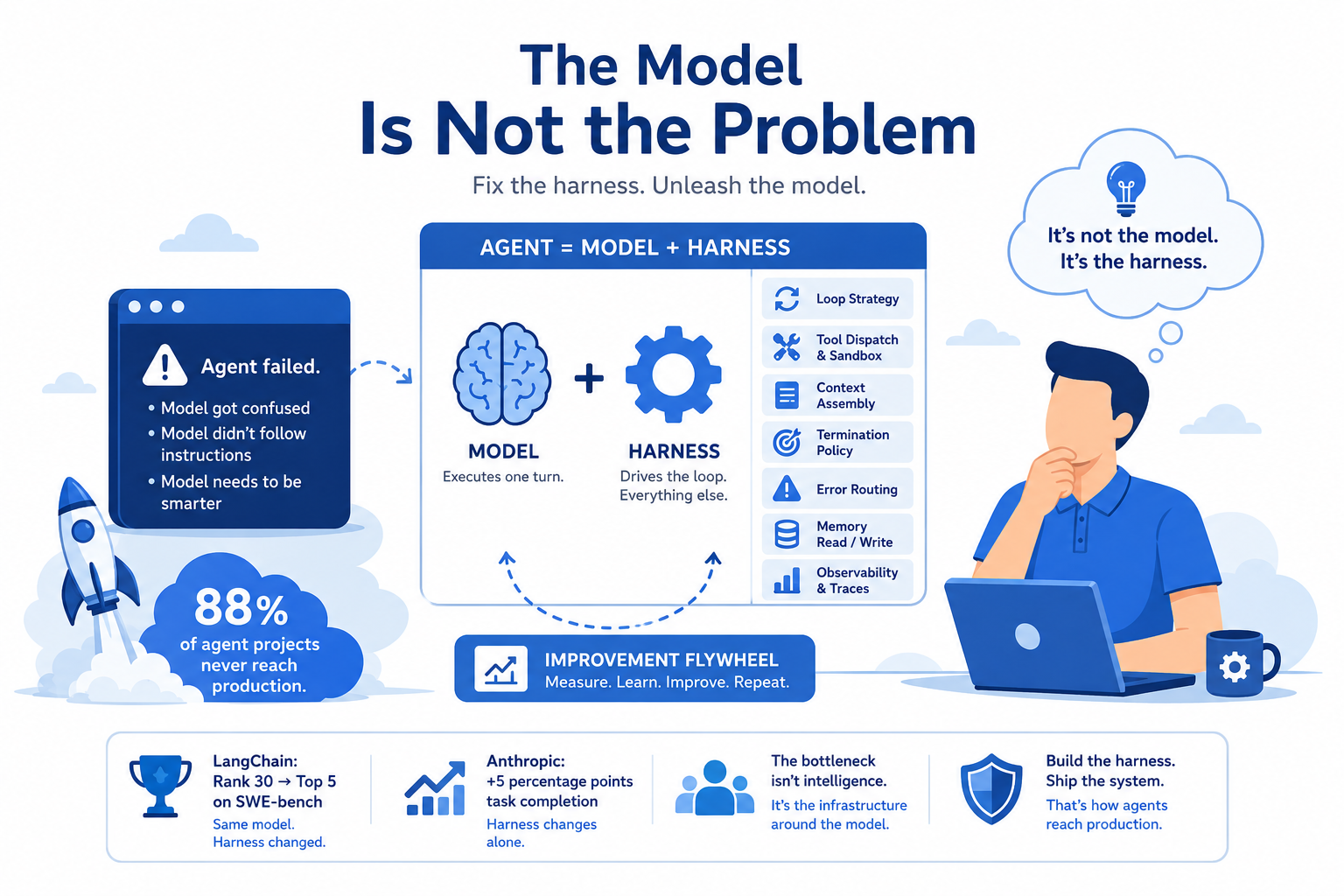
88% of agent projects never reach production. Not because the models aren't good enough.
I've watched teams spend months tuning prompts, swapping models, chasing benchmark improvements... and still ship nothing. The model keeps getting blamed. The model is almost never the problem.
Here's what the data actually shows: when LangChain changed their harness configuration (same model, no prompt changes) they went from rank 30 to top 5 on SWE-bench. Anthropic found that harness-level changes alone improved task completion rates by five percentage points without touching the underlying model. Five points. From configuration.
The equation most people are solving is wrong. They're treating Agent = Model when the real equation is Agent = Model + Harness. The model is fixed. The harness is the variable. And almost nobody is treating the harness as a first-class engineering problem.
That's what this series is about.
The Failure You're Blaming on the Model
You run an agent. It fails. You look at the output and think: the model got confused, or the model didn't follow instructions, or the model needs to be smarter.
Sometimes that's true. Usually it isn't.
What you're more likely looking at is one of these:
The agent ran out of context budget and started ignoring earlier instructions. Not a model failure, a context management failure. The agent declared the task complete after three tool calls when it needed twelve. Not a model failure, a termination policy failure. The agent hallucinated a tool call schema because the real schema was buried in turn 8 of a compacted conversation. Not a model failure, a context assembly failure. The agent went off the rails on the fourth turn because there was no sensor checking its output for drift. Not a model failure, a missing sensor.
Every one of these is a harness failure wearing a model failure mask. And because we don't have a name for harness engineering yet, we don't know where to look.
Three Data Points That Should Change How You Think About This
The LangChain finding is the one I keep coming back to. Going from rank 30 to top 5 on SWE-bench with the same model isn't a marginal improvement... it's a reordering of the leaderboard. The configuration changed. The model didn't. If model quality were the primary driver of agent performance, this shouldn't be possible.
The Anthropic 5-percentage-point finding is subtler but maybe more important. Five points of task completion improvement from harness changes sounds modest until you think about what it means at scale. If you're running a thousand agent tasks per day, five points is fifty more successful completions... every day, from work that has nothing to do with the model.
The 88% production failure rate is the one that indicts the whole industry. Most of these projects aren't failing because GPT-4 can't do the thing. They're failing because the environment around the model (the loop, the context, the tools, the termination conditions) was never engineered. It was hacked together and hoped at.
All three findings point at the same thing: the model's intelligence is not the bottleneck. The infrastructure around the model is.
Prompt Engineering, Context Engineering, Harness Engineering
These three things are related but not the same, and conflating them is expensive.
Prompt engineering is what you say to the model in a single turn. Real leverage... a well-crafted prompt outperforms a sloppy one... but it's local. It doesn't survive context window overflow. It doesn't help when the agent is on turn nine and has forgotten what turn three said. It doesn't tell the harness when to stop.
Context engineering is what information is in the context window and how it's structured. Andrew Ng has been pushing this framing and he's right that it's underappreciated. Where in the context does the system prompt live? How are tool results formatted? What gets compacted when the window fills up? These decisions matter enormously for model behavior, and they're not prompt decisions. They're context decisions.
Harness engineering is everything else. The loop strategy. How tools are dispatched and sandboxed. How the termination policy decides the run is done. How errors route. How memory reads and writes between turns. How the traces that feed the improvement flywheel get emitted. The full runtime environment that drives the agent lifecycle... and it's almost entirely absent from the current conversation.
Prompt engineering gets all the attention. Context engineering is having a moment. Harness engineering is where most of the remaining leverage is.
What a Harness Actually Is
Not a framework. Not a wrapper. A runtime container.
The distinction matters. A wrapper adds a layer around something. A framework gives you structure to fill in. A container drives execution. It accepts pluggable components and calls them according to a lifecycle.
The harness drives the loop. The model executes one turn. That's the most important sentence in this post.
Every turn, the harness assembles the context window, calls the agent, gets a response, dispatches any tool calls through a sandboxed executor, checks the sensor chain for drift or problems, evaluates the termination policy, decides whether to keep going, and emits observability spans for the whole thing. The model's job in all of this is to execute one turn of reasoning. That's it. Everything else is the harness.
What the harness owns:
- Loop execution and loop strategy selection
- Tool dispatch and sandbox enforcement
- Context assembly (what goes in the window and in what order)
- Termination evaluation (deciding when the run is actually done)
- Error routing (what halts, what retries, what escalates)
- Memory read/write (episodic records this session, semantic knowledge across sessions)
- Observability emission (the traces that make everything else auditable and improvable)
What it explicitly doesn't own: model intelligence, world knowledge, reasoning. Those belong to the model. The harness doesn't try to make the model smarter. It makes the environment rigorous enough that the model's actual intelligence can do its job.
Harness failures look like model failures until you have the vocabulary. Once you do, you start seeing them everywhere.
Why We Built spore-core
I've been building agent systems long enough to have made every harness mistake in sequence. Context that grew until the model lost track of its own instructions. Termination policies that amounted to "run until the model says it's done"... which meant the model declared victory early, constantly. Tools with no sandbox that occasionally did things they weren't supposed to. No observability, so when something broke I was debugging blind.
Every framework I tried had the same problem: the harness was an afterthought. You got a loop, some tool dispatch, maybe a memory abstraction. Scaffolding, not a system. No termination policy worth the name. No sensor chain. No structured approach to context assembly. No improvement flywheel. Every team I saw using these frameworks was rebuilding the same pieces on top of them, inconsistently, in ways that didn't compose.
spore-core is what I wanted to exist. A harness that is itself a first-class engineering artifact. Typed, testable, composable, observable. Every component has a clear interface and a clear responsibility. You can swap any of them for a test double without touching the rest. The traces it emits are structured well enough to run an improvement loop on.
The Spore micro-agent platform sits on top of spore-core. The harness is the foundation. This series is about building it from scratch, one component at a time, with the reasoning behind every decision made explicit.
What's Coming
The next post is the one that surprised me most when I was working through the design: what's the right mental model for a harness? The obvious answer is layers. That's wrong, and getting it wrong causes real problems downstream. I'll show you why inversion of control is the right abstraction and what it buys you.
After that: the agent loop and why "it's just a while loop" undersells it, sandbox isolation without Docker overhead, context as a budget not a dump, termination policy, two fundamentally different kinds of memory, the improvement flywheel, human-in-the-loop without blocking the thread, multi-agent patterns, building the harness in four languages, observability as the foundation rather than the afterthought, and what an external code review of the spec caught that the design phase missed.
If you've ever shipped an agent system and spent more time fighting the environment than the actual problem... the model was probably fine. The harness needed work.
Post 1 of 15 in Building Spore: An Agentic Harness from First Principles. Next: The Wrong Mental Model (And the Right One)